Wprowadzenie do wykorzystania sztucznych sieci neuronowych w przemysłowych systemach sterowania

Artykuł opisuje wykorzystanie sztucznych sieci neuronowych (ANN) w układach sterowania, układach nieliniowych, symulacji regulatorów zoptymalizowanych czasowo oraz w modelach systemów sterowania (w fabrykach) opartych na ANN.
Czytając tytuł tego artykułu, moglibyście zapytać: „Czy warto czytać więcej o sztucznych sieciach neuronowych, pomyślnie wdrożonych już dziesiątki lat temu, zwłaszcza przy tysiącach artykułów o ANN znajdujących się w Internecie?”. Moja odpowiedź brzmi „Tak. Proszę kontynuować”.
Kiedy zainteresowałem się sieciami ANN, przeczytałem setki artykułów na ich temat. Tylko garstka z tych publikacji pomogła mi zrozumieć, jak działa sztuczna sieć neuronowa i jak może być wykorzystana w praktyce. Mimo to nie mogłem znaleźć żadnego artykułu o tym, jak można wdrożyć przemysłowy system sterowania wykorzystujący ANN. Spędziłem setki godzin, eksperymentując z programowaniem w języku Python oraz symulacjami sieci ANN i systemów sterowania, dopóki wystarczająco nie zrozumiałem, jak sieć ANN działa w aplikacjach systemów sterowania.
Dzisiejsi specjaliści nie muszą już rozwiązywać problemów związanych z ANN od podstaw. Mogą korzystać z rozbudowanych bibliotek klas, funkcji itp. znajdujących się w materiałach pomocniczych (bibliotekach) wielu platform/języków programowania. Jeśli jednak mamy najpierw zrozumieć podstawy wykorzystywania sieci ANN w systemach sterowania, to ten artykuł powinien nam w tym pomóc.
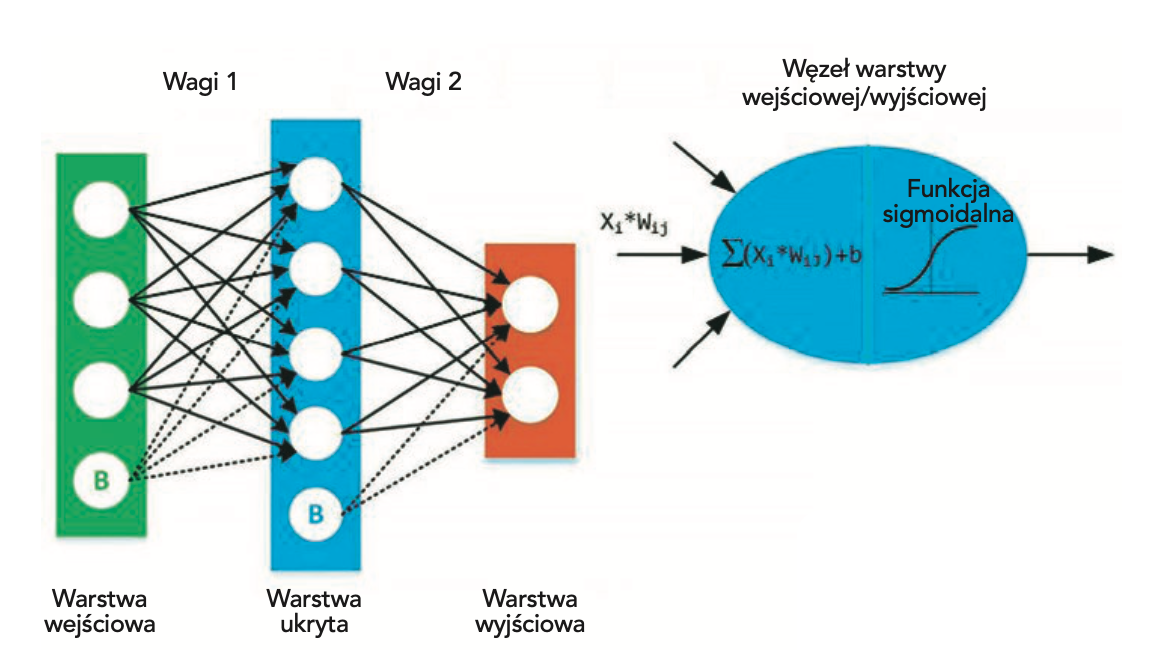
Podstawowe informacje o sieciach neuronowych
Sieci neuronowe starają się naśladować zdolności mózgu człowieka i zwierząt. Najważniejszą z tych zdolności jest zdolność do adaptacji. Chociaż nowoczesne komputery mogą przewyższać ludzki mózg pod wieloma względami, to wciąż są one urządzeniami „statycznymi” i dlatego nie potrafią wykorzystać całego swojego potencjału. Zastosowanie sztucznych sieci neuronowych polega na próbach wprowadzenia do komputera funkcjonalności mózgu poprzez kopiowanie zachowań biologicznych układów nerwowych. Możemy sobie wyobrazić sieć neuronową jako pewną funkcję matematyczną, która odwzorowuje dany zbiór wejściowy na pożądany zbiór wyjściowy. W skład sieci neuronowych wchodzą z następujące elementy:
– jedna warstwa wejściowa, x;
– jedna lub więcej warstw ukrytych;
– jedna warstwa wyjściowa, ŷ;
– zbiór wag i biasów pomiędzy każdą warstwą, W i b;
– funkcja aktywacji dla każdej warstwy ukrytej, σ.
Po prawej stronie rysunku 1 widzimy jeden taki (j-ty) węzeł warstwy ukrytej. Na początku sumuje on wszystkie sygnały pochodzące z węzłów wejściowych (i-tych) Każdy z nich został przetworzony – pomnożony przez swój współczynnik wagi. Zanim sygnał sumy opuści wyjście węzła, przechodzi przez funkcję aktywacji – ogranicznik. Najpopularniejszym ogranicznikiem jest funkcja sigmoidalna S(x), ponieważ można ją stosunkowo prosto zróżniczkować:
S(x) = 1 / (1 + e-x)
Podobne węzły wykorzystywane są w warstwie wyjściowej, tyle że ich sygnały wejściowe pochodzą z węzłów warstwy ukrytej.
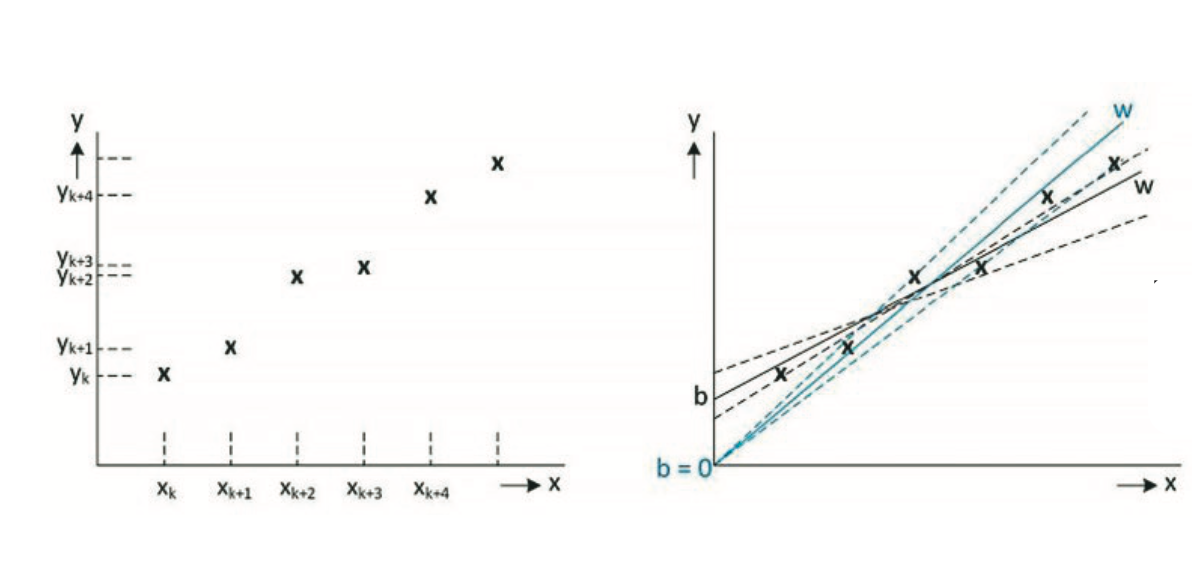
Prawidłowe wartości współczynników wagi decydują o sile przewidywań, tj. precyzji, z jaką zbiór wejściowy zostanie przekształcony w zbiór wyjściowy. Na rysunku 2 przedstawiono typowe mapowanie zbiorów: wejściowy → wyjściowy (po lewej stronie) oraz sposób, w jaki sieć ANN może przybliżyć takie mapowanie za pomocą funkcji liniowej y = W x + b (po prawej stronie). Odpowiednie mapowanie można znaleźć nawet bez zastosowania biasu (przesunięcia, offsetu), jednak ogólnie dodanie tego przesunięcia powinno dać lepsze przybliżenie. Dodanie większej liczby warstw ukrytych umożliwia nawet mapowanie nieliniowe.
Proces dokładnego dostrajania współczynników wagi z węzłów warstwy wejściowej i ukrytej jest nazywany trenowaniem sieci neuronowej. Każda iteracja procesu trenowania składa się z następujących kroków:
- Obliczenie przewidywanego wyjścia ŷ, proces określany jako „feedforward” (sprzężenie wyprzedzające).
- Aktualizacja współczynników wagowych, proces określany jako „backpropagation” (propagacja wsteczna).
Wyjście ŷ dla prostej 2-warstwowej sieci neuronowej oblicza się jako:
ŷ = ϐ(W2ϐ(W1x + b1) + b2)
Przewidywane wyjście ŷ będzie naturalnie różnić się od pożądanego wyjścia y, przynajmniej na początku procesu treningu. Jak duża jest ta różnica, mówi nam funkcja straty. Istnieje wiele dostępnych funkcji straty, jednak prosta suma kwadratów błędów, gdzie y jest pożądanym wyjściem, będzie dobrą taką funkcją.
Naszym celem trenowania sieci neuronowej jest znalezienie najlepszego zbioru wag, który minimalizuje funkcję straty. Matematycznie rzecz biorąc, musimy znaleźć ekstremum funkcji straty (w naszym przypadku minimum). Taka funkcja straty nie zależy tylko od jednej zmiennej (x). Może to być funkcja wielowymiarowa, której wykres posiada złożony kształt z wieloma lokalnymi minimami. Naszym celem jest znalezienie globalnego minimum funkcji straty.
Znajdźmy pierwszą pochodną funkcji sumy kwadratów błędów, ∂Loss(y,ŷ)/∂W. Niestety, nasza funkcja straty nie zależy bezpośrednio od współczynników wagi, musimy więc zastosować następującą regułę łańcuchową do obliczenia jej pochodnej:
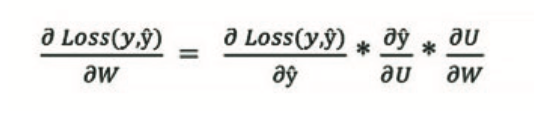
gdzie U = (Wx + b)
Obliczenie pierwszej pochodnej cząstkowej daje wynik: 2(y – ŷ)
Obliczenie drugiej pochodnej cząstkowej daje wynik: ϐ’
A ostatnia pochodna cząstkowa to po prostu: x
Na końcu otrzymamy: ∂Loss(y,ŷ)/∂W = 2(y – ŷ)* ϐ’ * x i to właśnie będziemy musieli zaimplementować, jako proces propagacji wstecznej. Zaletą użycia funkcji sigmoidalnej jest prosta implementacja jej pochodnej, ϐ’:
ϐ'(u) = ϐ(u)(1 – ϐ(u))
Powyższy wzór opisuje sposób postępowania:
Uruchamiamy proces propagacji wstecznej od wyjścia sieci neuronowej do warstwy ukrytej, która leży przed warstwą wyjściową i która jest połączona z warstwą wyjściową poprzez wagi W2. Ten sam proces musi być zastosowany ponownie od warstwy ukrytej do warstwy wejściowej, która jest połączona z warstwą ukrytą za pomocą wag W1. Pierwszy człon łańcucha w pochodnej funkcji straty w warstwie ukrytej, ∂Loss(h,ĥ)/∂ĥ będzie musiał być obliczony inaczej, ponieważ nie znamy jednoznacznie pożądanych wartości warstwy ukrytej h. Będziemy musieli obliczyć je z wartości wyjściowych.
1 artificial neural networks; ANN
2 ang. limiter
3 ang. fine-tuning
Peter Galan jest emerytowanym inżynierem oprogramowania systemów sterowania.


